Artificial Intelligence in Real-Time-Simulations
Projekttitel 1.1
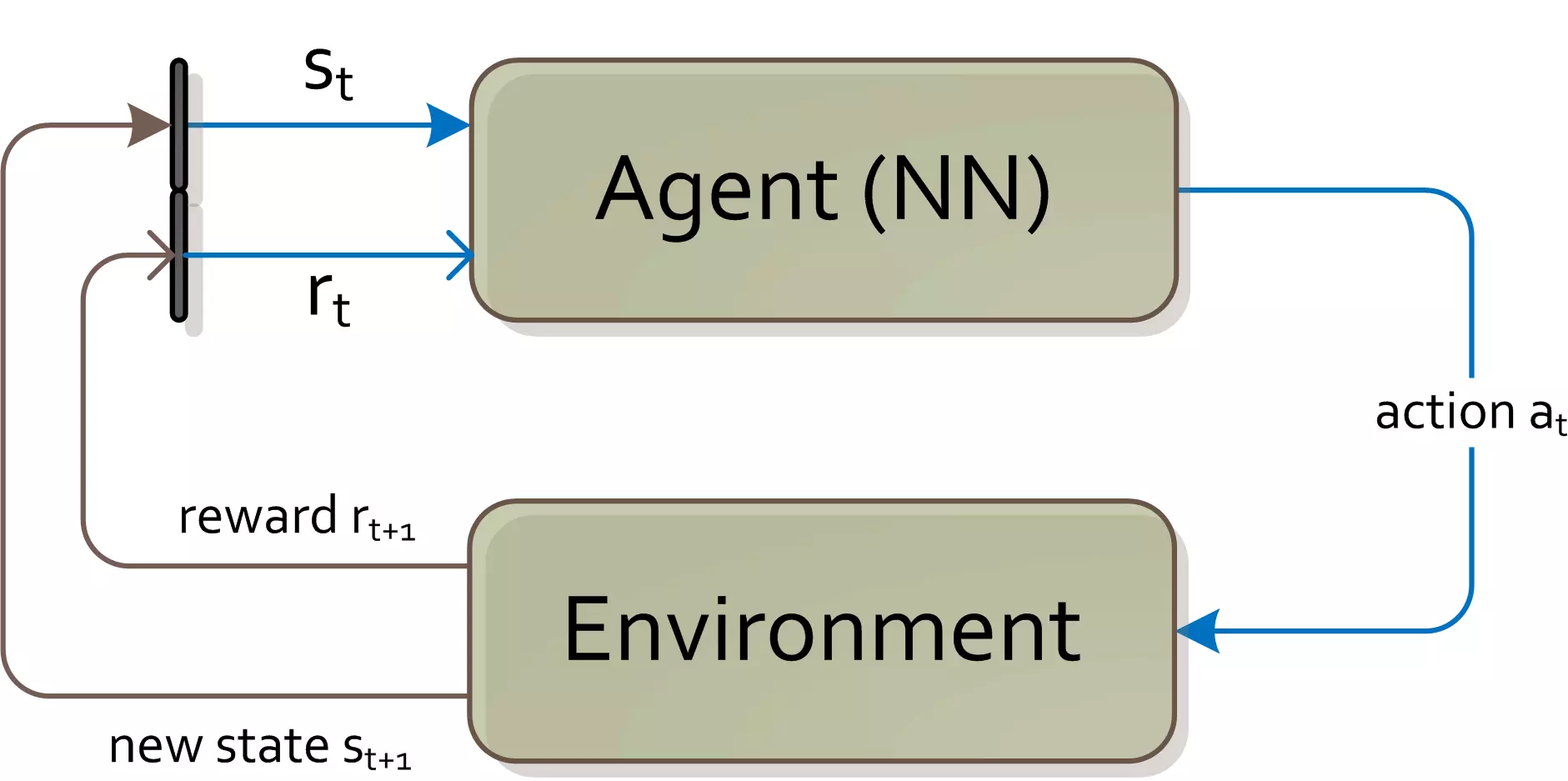
Deep-Learning Methoden (Reinforcement Learning Algorithmen mit Q-Learning) wurden eingesetzt, um eine optimale Handlungsstrategie in einer Echtzeitsimulation zu finden.
Die Komplexität von Computergegnern in Spielsimulationen ist über die letzten Jahren stetig gewachsen. Dennoch werden nach wie vor “straightforward”-Methoden zur Modellierung und Implementierung des Spielegegnerverhaltens eingesetzt. Traditionellerweise erfolgt die Verhaltenssteuerung durch Regelsysteme, zustandsbasierte Methoden und in jüngster Zeit mittels Fuzzy Logik. Dabei wird der aktuelle Zustand des Spiels durch eine Reihe abstrakter, von Hand gewählten Merkmale charakterisiert und die Aktionen werden je nach Zustand entweder deterministisch oder zufallsgetrieben generiert. Die Regeln und Strategien müssen von den Entwicklern einzeln codiert werden und setzen ein grosses Wissen über die Spielmechanik voraus.

Diese bisher eingesetzten Methoden haben jedoch Nachteile und Limitationen, welche sich bei sogenannten Deep-Learning-Verfahren, insbesondere beim Reinforcement Learning, nicht zeigen. Beispielsweise erlauben es traditionelle Methoden dem Spieler häufig das Verhalten des Gegners zu durchschauen, da nur eine limitierte Anzahl von Taktiken und Strategien möglich sind. Dadurch kann der Spieler die Schwächen des Gegners leicht ausnützen und das Spiel verliert durch fehlende Herausforderung schnell an Unterhaltungswert.
Artifizielle Neuronale Netze, insbesondere Reinforcement Learning Networks, haben im Vergleich zu anderen Lernverfahren den Vorteil, dass es kein sogenanntes “Supervised-Learning-Verfahren” ist und deshalb keine Spielabläufe von echten Spielern braucht. Beim Reinforcement Learning wird die artifizielle Intelligenz solange gegen sich selber spielen (mittels der Simulation von Spielvarianten), bis sie das Spiel beherrscht. Als Eingabe für diese Lernverfahren dient lediglich der Zustand des Spiels zusammen mit der Belohnung (Sieg oder Niederlage) und nicht wie ein anderer Spieler auf diesen Zustand reagieren würde.
Dies ist ein wesentlicher Vorteil gegenüber anderen Lernmethoden (beispielsweise Supervised Learning/begleitetes Lernen), da einerseits das Sammeln von Spielerdaten sehr aufwändig ist und diese zum anderen bereits schon bei kleineren Anpassungen des Spiels erneut gemacht werden muss.