Skalierbare datengetriebene Modellierung von Finanzrisiken
Eine skalierbare, datengetriebene Plattform zur Modellierung von Finanzrisiken auf Basis von Einzelpositionen erlaubt es den Anwendern, flexibel und kosteneffizient auf regulatorische Anforderungen zu reagieren.
Ariadne Software AG (ASW) ist ein Schweizer Start-up, das eine SaaS-Plattform für die integrierte Finanzanalyse betreibt. Die Plattform richtet sich an Finanzplanungs-, Treasury- und Risikomanagement-Abteilungen sowie an Entscheidungsträger auf Unternehmensebene. Die Integration der Sichtweisen verschiedener Departments zusammen mit der Möglichkeit der Abbildung von kleinen und mittleren bis hin zu grossen Instituten macht diese Plattform sehr flexibel in der Anwendung, stellt gleichzeitig aber hohe Anforderungen an die Skalierbarkeit des Systems.
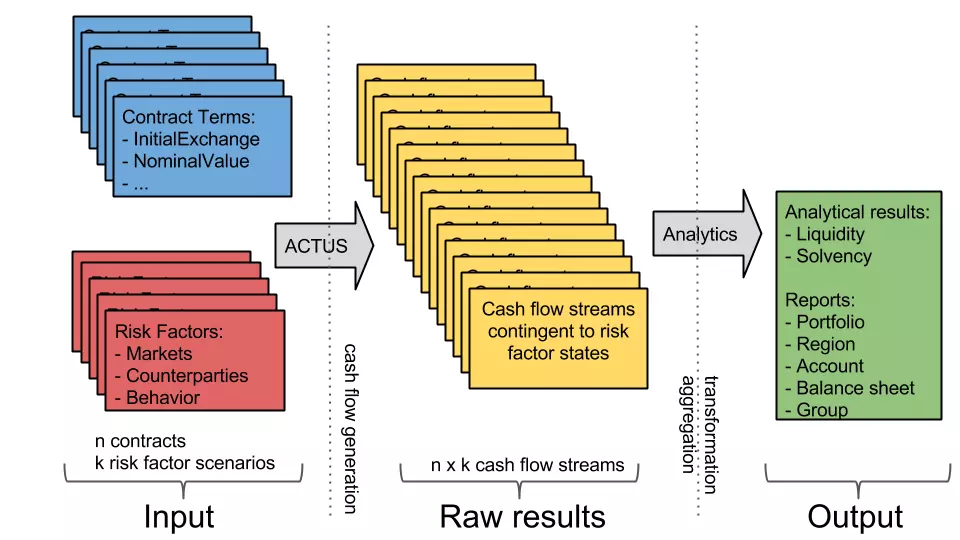
Die Finanzanalysen auf dieser Plattform werden konzeptuell immer nach demselben Schema durchgeführt, siehe Bild:
- Der Input besteht aus einem Set von Finanzkontrakten sowie einem Set von ökonomischen Szenarien;
- diese beiden Sets werden dann paarweise zu einem Set von zukünftigen Cashflows pro Kontrakt-Szenario-Paar kombiniert;
- Finanzanalysen werden nun auf dieser neuen Cashflow-Datenbasis durchgeführt;
- schliesslich werden diese granularen Resultate noch nach verschiedenen, nutzerdefinierten Kriterien aggregiert.
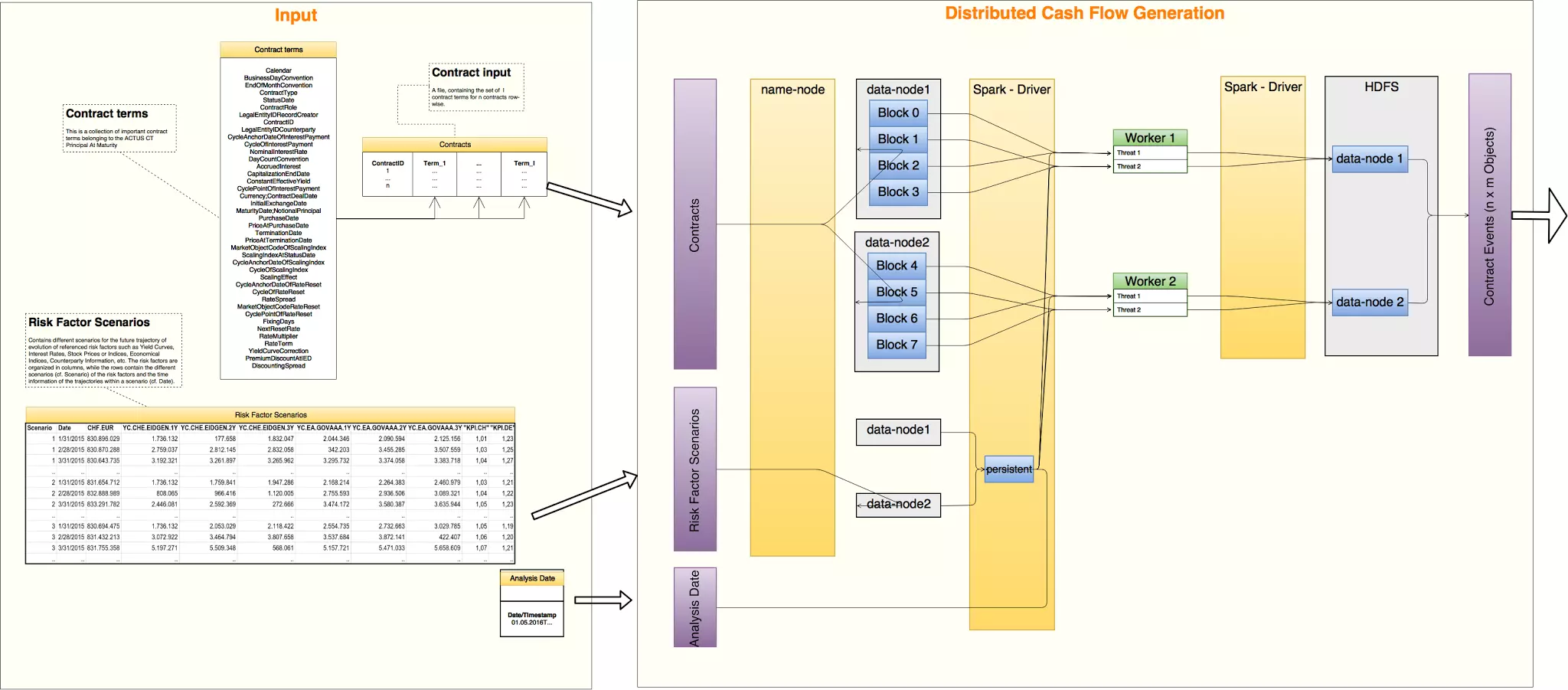
Während kleine Finanzinstitute zehntausende von Finanzkontrakten auf ihren Bilanzen haben, gehen die Schätzungen für die Anzahl von Kontrakten in den Büchern grosser Institute in die bis zu Hunderte von Millionen. Auf der anderen Seite erfordern aussagekräftige Finanzanalysen die Simulation dieser Kontrakte nach wenigen einfachen ökonomischen What-If Szenarien, oder innerhalb von Monte-Carlo Simulationen, die aus tausenden oder zehntausenden von stochastischen "Szenarien" bestehen. Um die grossen Datenmengen effizient verarbeiten zu können, wurde im Rahmen unseres Projekts ein neuer, verteilter Rechenkern entwickelt, der auf neuartigen open-source Big Data-Technologien basiert.
Die Verwendung eines solchen verteilten Kerns ist aus mehreren Gründen vorteilhaft:
- Kosteneffizienz hinsichtlich des Aufbaus eines gewünschten Leistungsniveaus durch einen Cluster von Low-End-Rechenknoten gegenüber einem einzelnen High-End-Knoten;
- Kosteneffizienz im Hinblick auf On-Demand-Einschalt- / Ausschalt-Berechnungsknoten für Simulationen;
- erhöhte Zuverlässigkeit eines Clusters von Rechenknoten im Vergleich zu einer einzelnen "Single-Point-of-Failure" -Maschine;
- Durchführbarkeit von Simulationen im großen Massstab.