Google-Forscher präsentiert Highlights im Gebiet Computer Vision auf CAI-Kolloquium
Am 30. März 2022 begrüssten wir einen besonderen Gast bei unserem CAI-Kolloquium. Dr. Lucas Beyer, Senior Research Engineer bei Google Brain, präsentierte die neuesten Durchbrüche bei der Anwendung von Transformer-Architekturen im Bereich Computer Vision.
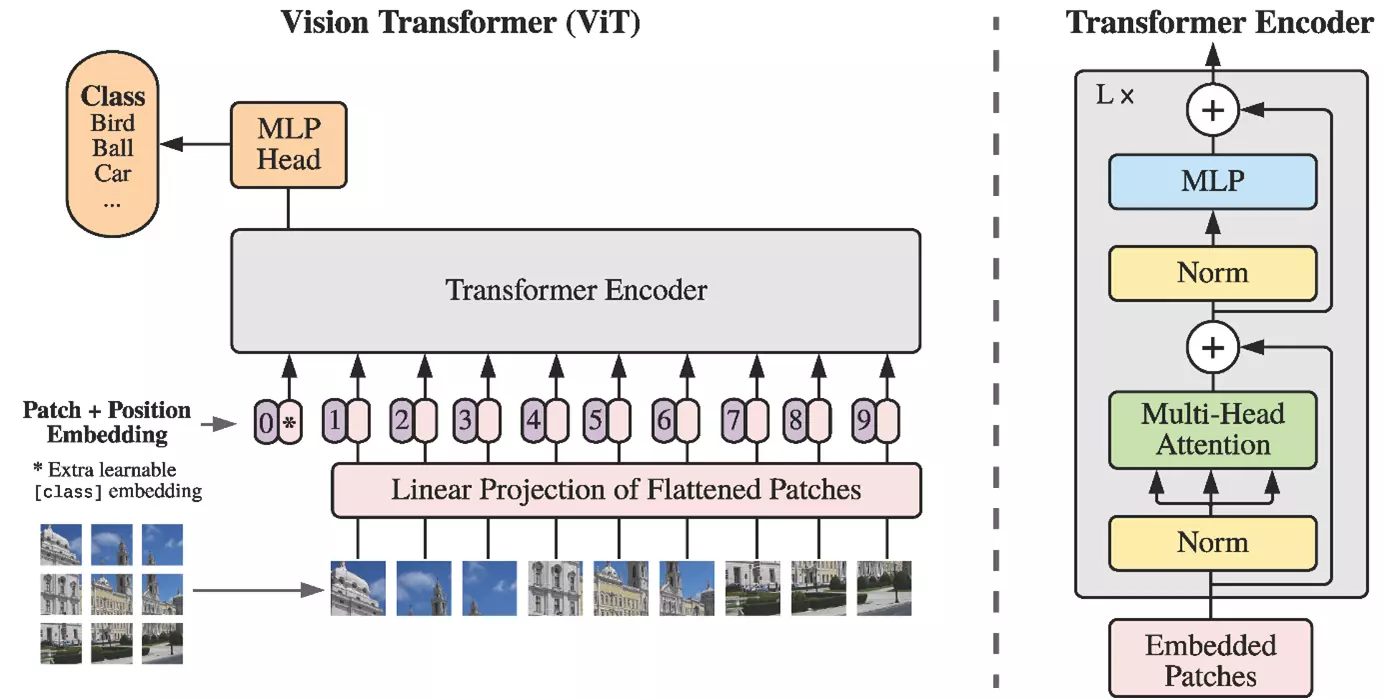
Deep-Learning-Architekturen auf der Grundlage sogenannter Convolutional Neural Networks (CNNs) haben sich bei der Lösung von Computer Vision (CV) Problemen wie Bildklassifizierung oder Objekterkennung als erfolgreich erwiesen. Andererseits wurden in den letzten Jahren Meilensteine im Bereich Natural Language Processing (NLP) erzielt, z.B. bei Texterzeugung und -verständnis oder der maschinellen Übersetzung, indem sogenannte Transformer in großen Sprachmodellen wie GPT oder BERT eingesetzt wurden. Solche Transformer-Architekturen werden nun auch im Bereich Computer Vision eingesetzt, und zwar mit großem Erfolg. Diese Entwicklung wurde von Google Research massgeblich vorangetrieben. Daher begrüssten wir Dr. Lucas Beyer, Senior Research Engineer bei Google Brain in Zürich und einen der Co-Autoren mehrerer vielfach zitierter Forschungspublikationen in diesem Bereich, zu unserem CAI-Kolloquium, um uns einen «deep dive» in die technischen Details und Durchbrüche bei der Anwendung von Transformern im Bereich Computer Vision zu geben, etwa in der bekannten ICLR-Publikation "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" (https://arxiv.org/abs/2010.11929), in dem der Vision Transfomer (ViT) vorgestellt wurde. Beyer berichtete ausserdem über Google’s jüngste Forschungsarbeiten, darunter "How to train your ViT?" (https://arxiv.org/abs/2106.10270), eine Untersuchung der derzeitigen Grenzen des ViT bei der Skalierung ("Scaling ViT", https://arxiv.org/abs/2106.04560) und schloss mit der Vorstellung einer neuen Alternative zum typischen Transfer-Learning-Ansatz, dem sogenannten Locked Image-Text-Tuning ("LiT-tuning", https://arxiv.org/abs/2111.07991).
Das Kolloquium war daher sowohl für die NLP- als auch für die CVPC-Forschungsgruppe des CAI von grosser Bedeutung, insbesondere im Hinblick auf die kürzlich geäusserte Absicht beider Gruppen, ihre Kräfte zu bündeln und an anspruchsvollen Aufgaben zu arbeiten, die multimodale Eingabedaten (Kombination von zwei oder mehr Modalitäten wie Text, Bild, Video, Audio oder Tabellen) umfassen, was ein ideales Anwendungsgebiet für Transformer-basierte Architekturen sein könnte. In diesem Zusammenhang haben wir kürzlich über die Databooster-Plattform einen Aufruf zur Teilnahme veröffentlicht, in dem wir potenzielle Projektpartner mit entsprechenden Use Cases auffordern, sich unserer Zusammenarbeit anzuschliessen.
Weitere CAI-Kolloquien sind in Planung. Die nächste Veranstaltung wird eine Podiumsdiskussion zum Thema "Pathways beyond present AI" sein, die vom renommierten Computer- und Neurowissenschaftler Prof. Dr. Christoph von der Malsburg (Frankfurt Institute of Advanced Sciences, derzeit Gastprofessor an der UZH/ETHZ sowie an der ZHAW) eingeleitet und von Dr. Ricardo Chavarriaga, Leiter des CLAIRE-Büros Schweiz, moderiert wird. Die Veranstaltung findet am Mittwoch, 27. April 2022, statt.