Google Researcher presents Computer Vision Highlights at CAI Colloquium
On March 30, 2022, we welcomed a special guest at our CAI colloquium. Dr. Lucas Beyer, senior research engineer at Google Brain, presented the most recent breakthroughs in applying transformer architectures to computer vision.
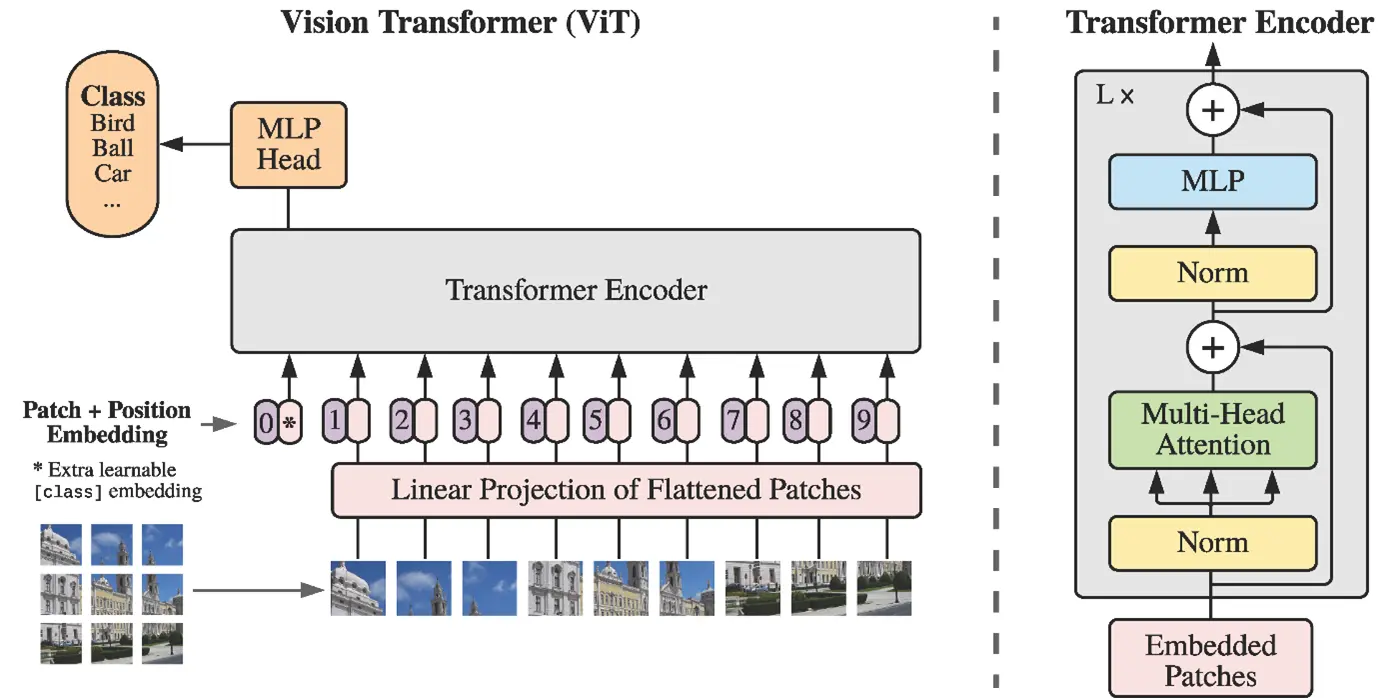
Deep learning architectures based on so-called Convolutional Neural Networks (CNNs) have proven to be successful in solving computer vision (CV) tasks such as image classification or object detection. On the other hand, recent years have seen breakthroughs in natural language processing (NLP) tasks, e.g. text generation and understanding or automatic translation, by employing so-called Transformers in huge language models such as GPT or BERT. Such transformer architectures have now also been applied to computer vision, and with great success. This development has been spearheaded by Google research. Therefore, we welcomed Dr. Lucas Beyer, a senior research engineer with Google Brain in Zurich and one of the co-authors of several highly cited research publications in this domain, to our CAI colloquium to give us a deep-dive into the technical details and breakthroughs in the application of transformers in computer vision, e.g. as discussed in the famous ICLR paper “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” (https://arxiv.org/abs/2010.11929), where the Vision Transformer (ViT) was introduced. He also covered their most recent research, including “How to train your ViT?” (https://arxiv.org/abs/2106.10270), an exploration of its current limits at scale (“Scaling ViT”, https://arxiv.org/abs/2106.04560), and concluded by introducing a recent new alternative to the typical transfer-learning approach, locked image-text tuning (“LiT-tuning”, https://arxiv.org/abs/2111.07991).
The colloquium was thus very relevant to both the NLP and CVPC research groups at CAI, especially in the light of the recent expressed intent of both groups to join forces and work on challenging tasks providing multi-modal input data (combining two or more of text, images, video, audio or tabular data), which could be an ideal application domain of transformer-based architectures. In this context, a recent call for participation has been issued by us via the Databooster platform, calling on potential use case providers to join our collaboration.
Future CAI Colloquia are being planned. The next event will be a panel discussion “Pathways beyond present AI”, introduced by renowned Computer- and Neuroscientist Prof. Dr. Christoph von der Malsburg (Frankfurt Institute of Advanced Sciences, currently guest professor at UZH/ETHZ as well as at ZHAW), and chaired by ZHAW’s Dr. Ricardo Chavarriaga, head of the CLAIRE office Switzerland. The event will take place on Wednesday April 27, 2022.