CAS Data Engineering
AnmeldenAuf einen Blick
Abschluss:
Certificate of Advanced Studies ZHAW in Data Engineering (12 ECTS)
Start:
22.08.2026
Dauer:
132 Lektionen, mehr Details zur Durchführung
Kosten:
CHF 8'340.00
Bemerkung zu den Kosten:
- MAS-Teilnehmende erhalten einen Rabatt von CHF 1‘000.00
- die vollständigen Studiengebühren sind vor Studienbeginn zu begleichen
- in den Studiengebühren sind die Einschreibe- und Prüfungsgebühren sowie sämtliche kursrelevanten Unterlagen enthalten
Durchführungsort:
- ZHAW School of Management and Law / Campus St.-Georgen-Platz, 8401 Winterthur
- Online
- An Freitagen am Campus ZHAW School of Management and Law, Winterthur; Samstage finden i.d.R. online statt; ausgenommen von Tagen mit Workshops und Leistungsnachweisen
Unterrichtssprache:
- Deutsch
- Das Unterrichtsmaterial ist teilweise in englischer Sprache.
Weiterführende Informationen:
Es besteht eine Präsenzpflicht von 80%.
Der CAS kann einzeln oder als Teil des MAS Business Engineering absolviert werden.
Ziele und Inhalt
Zielpublikum
Der CAS richtet sich an Fach- und Führungskräfte aus allen Branchen, welche ein Grundlagenverständnis für das Datenmanagement mitbringen, bereits Erfahrungen im generellen Umgang mit Daten gesammelt haben (bspw. durch den Besuch des CAS Data Competence for Business) und sich im Bereich der Sammlung, Aufbereitung, Validierung und Distribution von Daten vertiefen wollen. Idealerweise haben Sie bereits erste Erfahrungen mit 1 – 2 Abfrage-, Programmier- oder Skriptsprachen gesammelt. Der CAS bereitet Sie darauf vor, Aufgaben im Bereich des Data Engineering selbst durchzuführen sowie auf einem fachlichen Niveau zu überwachen.
Ziele
Sie können im Anschluss an diesen CAS:
- Fragestellungen identifizieren, denen mit dem Einbezug von Daten und unterschiedlichen Aufbereitungs- und Analysemethoden begegnet werden kann
- für den Erkenntnisgewinn erforderliche Daten identifizieren und spezifizieren
- Speicherlösungen konzeptionieren und Datenmodelle skizzieren
- Daten mittels unterschiedlicher Vorgehensweisen beschaffen und in geeignete Speicherlösungen überführen
- für die Datenpipeline geeignete Transformationsmethoden kennen und anwenden, um die Datenkompatibilität herzustellen
- für die Datenpipeline geeignete Bereinigungsmethoden kennen und anwenden, um eine akzeptable Datenqualität herzustellen
- Grundsätzliche Überlegungen und Wege zur Bereitstellung von Daten für die Anwendungsfälle Analytik und Machine Learning kennen
- die wichtigsten Überlegungen im Bereich der Informationssicherheit kennen
- Überlappungen des Data Engineering – Lebensyzklus mit Datenmanagement, Orchestrierung, Software Engineeering und DevOps/DataOps/MLOps kennen
- Statistische Methoden und Modelle des maschinellen Lernens für die Analyse und Validation der Daten innerhalb des Data Engineering - Lebenszyklus kennen und anwenden
- Statistische Methoden und Modelle des maschinellen Lernens für die Identifikation von Anomalien in Daten kennen und anwenden
- Werkzeuge und Methoden für den Umgang mit natürlicher Sprache kennen und anwenden
- Werkzeuge und Methoden für den Umgang mit Bilddaten kennen und anwenden
- Werkzeuge und Methoden für den Umgang mit räumlichen Daten kennen und anwenden
- Daten über ausgewählte Deployment-Lösungen bereitstellen und Datenübergänge automatisieren
Zwei Perspektiven auf den Data Value Stack:
CAS Data Engineering vs. CAS Data Competence for Business
Der CAS Data Engineering fokussiert stärker auf die technischen Grundlagen, Architekturen und Prozesse entlang des Data Value Stack, während der CAS Data Competence for Business die geschäftliche Nutzung, Bewertung und verantwortungsvolle Einordnung von Daten- und KI-Anwendungen in den Vordergrund stellt.
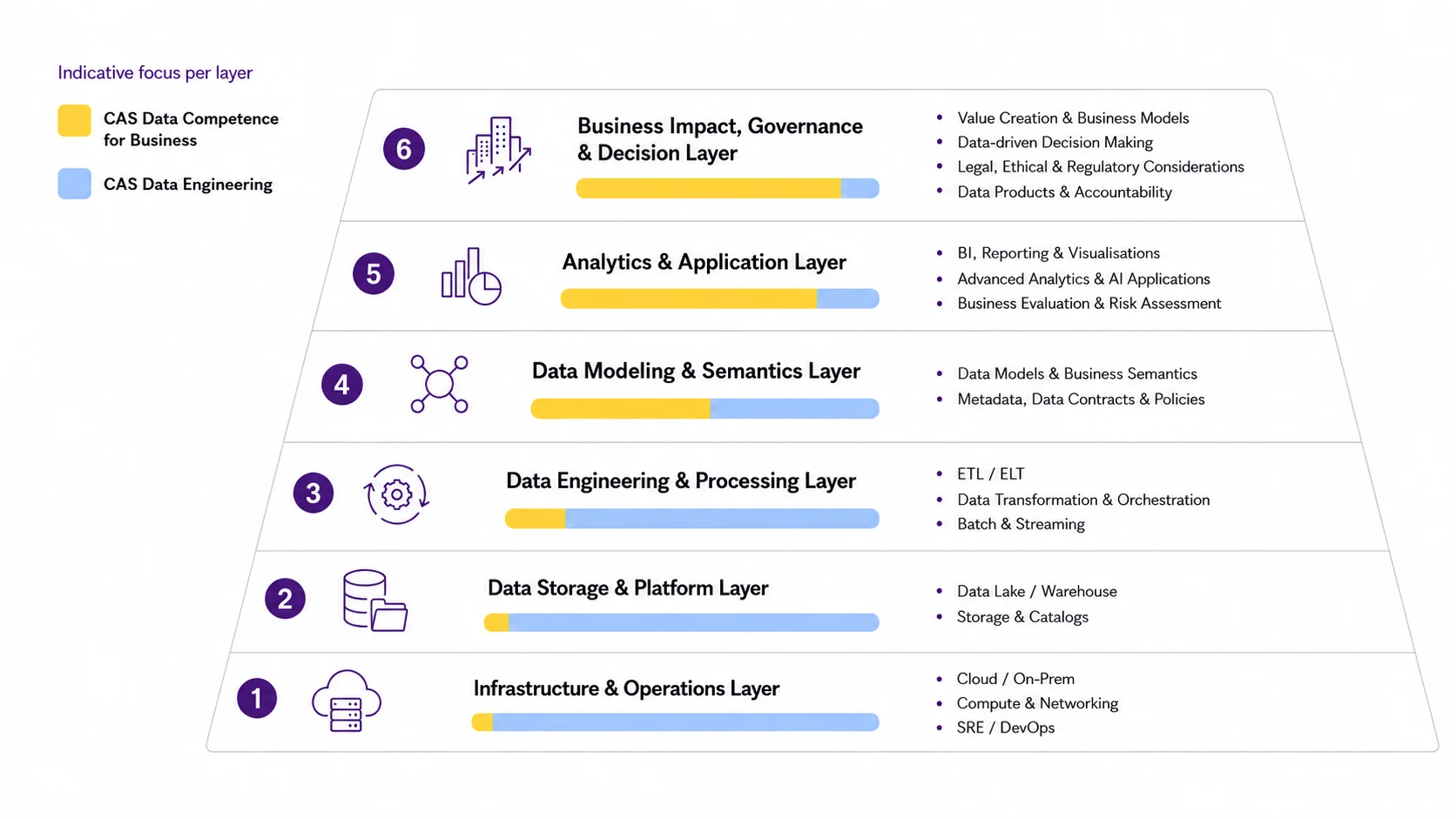
Inhalt
Data Engineering bildet die technische Grundlage moderner daten- und KI-getriebener Systeme. Während sich Data Science primär mit der Analyse, Modellierung und Interpretation von Daten befasst, konzentriert sich Data Engineering auf die Konzeption, Entwicklung und den Betrieb von Datenarchitekturen, Datenpipelines und Datenplattformen. Ziel ist es, Daten aus unterschiedlichen Quellen effizient zu erfassen, zu integrieren, zu transformieren und für analytische sowie operative Anwendungen nutzbar zu machen.
Mit dem rasanten Wachstum von Datenmengen, Cloud-Plattformen und Künstlicher Intelligenz steigt in Unternehmen die Bedeutung von Fachpersonen, die Daten entlang des gesamten Datenlifecycles systematisch bereitstellen, verarbeiten und verwalten können. Moderne Data-Engineering-Lösungen bilden heute die Grundlage für Business Intelligence, Machine Learning, generative KI, automatisierte Prozesse und datenbasierte Entscheidungsunterstützung.
Im CAS Data Engineering erwerben die Teilnehmenden praxisorientierte Kompetenzen zur Entwicklung moderner Daten- und KI-Systeme. Der CAS verbindet technische Grundlagen mit produktionsnahen Anwendungen und vermittelt ein breites Spektrum an Methoden, Werkzeugen und Architekturen aus den Bereichen Data Engineering, Data Science und AI Engineering.
Jeder Themenblock kombiniert theoretische Grundlagen, architektonische und prozessorientierte Perspektiven sowie umfangreiche praktische Übungen. Die Übungen basieren auf öffentlich zugänglichen Datensätzen aus unterschiedlichen Domänen wie Gesundheit, Energie, Mobilität, Versicherungen, Finanzen oder Industrie. Es besteht zudem die Möglichkeit, mit eigenen Daten und individuellen Anwendungsfällen aus dem beruflichen Umfeld zu arbeiten.
Modul 1: Werkzeuge und Methoden
Das erste Modul widmet sich den Werkzeugen und Methoden der folgenden Phasen des Data Engineering Lifecycle (Reis & Housley, 2022).
1. Einführung
- Definition von Data Engineering, Abgrenzung zu verwandten Themenbereichen
- Motivation, Organisation, Anforderungen, Organisatorisches
- Tools und Equipment (Programmier-, Abfrage- und Skriptsprachen, Umgebungen)
- Einführungscases
2. Architekturen
- Datenarchitekturen und ihrer Grundsätze
- Architekturkonzepte
3. Ingestion
- Formate und Datentypen
- Datenquellen und -identifikation
- API’s
- Webscraping
- Streaming
4. Storage
- Verteilte Systeme
- Datenbankeigenschaften
- Raw ingredients
- Data Storage Systems
5. Transformation
- ROI der Transformation
- Zeitfenster
- Kombination von Streams mit anderen Daten
- Kompatibilitäten
- Integration
- Datenqualität
6. Serving
- Überlegungen zur Bereitstellung von Daten
- Wege zur Bereitstellung von Daten
- Anwendungsfälle Analytik und Machine Learning
- Reverse ETL
7. Unterströmungen
- Datenmanagement
- Orchestrierung
- Software Engineering
- DevOps und DataOps
- Informationssicherheit
Modul 2: Domänen und Daten
Im 2. Modul stehen Anwendungsfälle in den folgenden Themenblöcken im Fokus.
1. Generative KI: Von Prompts zu RAG
2. Use Cases und Best Practices im Service Public
3. Plattformen und Aggregatoren
4. Agentic AI
5. Räumliche Daten
6. Bilddaten
Sprachen und Umgebungen
Wir arbeiten mit den folgenden Sprachen und Umgebungen.
Programmier-, Abfrage- und Skriptsprachen:
- Python
- SQL
- MongoDB Query Language (MQL)
- Cypher
- InfluxQL
- R (optional)
- Visual Basic (optional)
Frameworks und Libraries:
- pandas
- NumPy
- Matplotlib
- Seaborn
- scikit-learn
- TensorFlow / Keras (optional)
- Flask
- Dash
- LangChain
- Apache Spark
Entwicklungsumgebungen und Tools:
- OpenRefine
- Jupyter Notebook / JupyterLab
- Spyder
- Marimo
- Visual Studio Code
- GitHub Codespaces
- PyCharm (optional)
- Google Colab (optional)
- MS Excel
- MS Access (optional)
Datenmodelle und Datenbanksysteme:
- Relational: SQLite, MySQL, MariaDB
- Dokument-basiert: MongoDB
- Graphen-basiert: Neo4j
- Zeitreihen-basiert: InfluxDB
- Vektor-Datenbanken: pgvector, Chroma
- Lokale und cloudbasierte Datenplattformen und Datenbanksysteme (z.B. Microsoft Azure, Google Cloud Platform, Amazon Web Services)
KI und AI Engineering:
- Generative KI und Large Language Models (LLMs): ChatGPT, Claude, Gemini
- Lokale LLM-Umgebungen: Ollama
- Editor-integrierte KI: GitHub Copilot, Cursor
Weitere Technologien und Plattformen:
- Google Cloud Platform (GCP)
- Git
- Shell / Terminal
- Docker
- QT Designer (optional)
- Django (optional)
Der CAS kann einzeln oder als Teil des MAS Business Engineering bzw. des MAS IT-Leadership und TechManagement absolviert werden:
-
MAS Business Engineering
Themen:
- Informatik / Data Science / Ingenieurswissenschaften
- Management / Wirtschaft / Verwaltung
Abschluss: MAS (60 ECTS)
Gestalten Sie die digitale Zukunft mit dank des berufsbegleitenden MAS Business Engineering. Dieser vermittelt seit mehr…
-
MAS IT-Leadership und TechManagement
Themen:
- Management / Wirtschaft / Verwaltung
- Informatik / Data Science / Ingenieurswissenschaften
Abschluss: MAS (60 ECTS)
Mit dem MAS IT-Leadership und TechManagement bringen Sie sich selbst und die IT-Organisation auf Erfolgskurs. Dafür…
Methodik
Der CAS zeichnet sich durch methodische Vielfalt aus. Neben Lehrgesprächen, Referaten, (Gruppen-)Übungen, Fallstudien oder Arbeit an Fallbeispielen aus der Praxis wird grosser Wert auf den Erfahrungsaustausch zwischen den Teilnehmenden gelegt.
Leistungsnachweis
Der Leistungsnachweis besteht aus einer Projektarbeit, die den gesamten CAS begleitet und in Gruppen erarbeitet wird. Die Projektarbeit wird pro Modul im Rahmen eines Kolloquiums durch die Gruppen präsentiert und im Plenum diskutiert.
Mehr Details zur Durchführung
Die Vorlesungen finden jeweils am Freitag und Samstag statt. Änderungen sind möglich.
Beratung und Kontakt
-

Studienleitung:
Maria Rothstein
+41 58 934 42 52
E-Mail -
Weiterbildungsmanagement:
Anette Kizilelma
+41 58 934 45 58
E-Mail -
Administration:
Ayham Almasri
+41 58 934 46 33
E-Mail


Veranstalter
Dozierende
Frederic Auberson: Google
SRE for Data Engineers
“Site Reliability Engineering is Google's way of running services at scale. Because up to 90% of the cost of software is incurred after a service is launched, SREs make data-driven decisions in order to optimize the efficiency of systems operations. In this talk, we'll look at what an SRE does, where we get our data from, and how we leverage it in our day-to-day work.”
Prof. Dr. Alexandre de Spindler: Generative KI – Von Prompts zu RAG
Tibor Dudas: Informationssicherheit
Dr. Mario Gellrich: Ingestion und Räumliche Daten
Jasmin Heierli: Generative KI – Von Prompts zu RAG, Workshop, Leistungsnachweis
Dr. Christian Hitz: Einführung
Benjamin Kühnis: Agentic AI und Bilddaten
Václav Pechtor: Google Cloud Plattform (GCP)
Maria Rothstein: Einführung, Architekturen, Storage, Transformation, Serving, Unterströmungen, Use Cases mit kombinierten Fragestellungen, Workshop, Leistungsnachweis
Kirsten Scherer: Kantonspolizei ZH, SRG SSR
Use Cases und Best Practices im Umgang mit unstrukturierten Daten im Service Public
“Der Vortrag widmet sich den Aufgaben, die sich in der Praxis im Umgang mit unstrukturierten Daten ergeben können. Dazu werden drei Beispiele aus dem Umfeld des Service Public, deren spezifische Problemfelder und die gewählten Lösungsansätze vorgestellt. Anschliessend erfolgt einerseits ein Spotlight auf die allgemeinen Fähigkeiten, die zur Identifizierung von Daten und Verfahren für bestimmte Problemstellungen erforderlich sind und andererseits auf die besonderen Anforderungen, die die Nutzung unstrukturierter Daten im Unternehmen mit sich bringen kann.”
Dr. Anna Wiedemann, DevOps
Anmeldung
Zulassungskriterien
Der Zertifikatslehrgang richtet sich an Absolventinnen und Absolventen von Hochschulen (FH/Universität) mit mind. 3 Jahren Berufserfahrung sowie an Berufsleute ohne Hochschulabschluss mit mind. 5 Jahren Berufserfahrung und entsprechenden Weiterbildungsausweisen (höhere Fachschule oder höhere Fachprüfung mit eidg. Fachausweis/Diplom).
Englischkenntnisse werden vorausgesetzt, weil im Studiengang mit englischer Literatur gearbeitet wird.
Über die definitive Zulassung entscheidet die Studienleitung.
Anmeldeinformationen
Anmeldungen werden in der Reihenfolge des Eingangs berücksichtigt.
Startdaten und Anmeldung
| Start | Anmeldeschluss | Anmeldelink |
|---|---|---|
| 22.08.2026 | 10.07.2026 | Anmeldung |