Health and Environmental Analytics

Statistische Modellierung und Machine Learning machen komplexe Daten verständlich und liefern fundierte Erkenntnisse, für kluge Entscheidungen zu Gesundheits- und Umweltfragen in Wirtschaft, Wissenschaft und Politik.
Unsere Verfahren der Datenanalyse
- Statistische Methoden sind Werkzeuge zur Gewinnung und Auswertung von Daten. Sie unterstützen dabei, Trends zu identifizieren, Hypothesen zu validieren und datenbasierte Entscheidungen auch unter Unsicherheit zu treffen.
- Prädiktive Analytik nutzt statistische Modelle und Methoden des maschinellen Lernens, einschliesslich Ensemble-Verfahren und Deep Learning, um Daten zu analysieren und zukünftige Trends, Ereignisse oder Verhaltensweisen fundiert vorherzusagen.
- Spezielle Themen
- Kausale Inferenz
- Conformal Predictions
- Anonymisierung von Daten
- Versuchs- und Studiendesign
- Netzwerkanalyse
Forschung & Projekte
Modellbasierter Dreistufenklassifikator für Schwebestaub
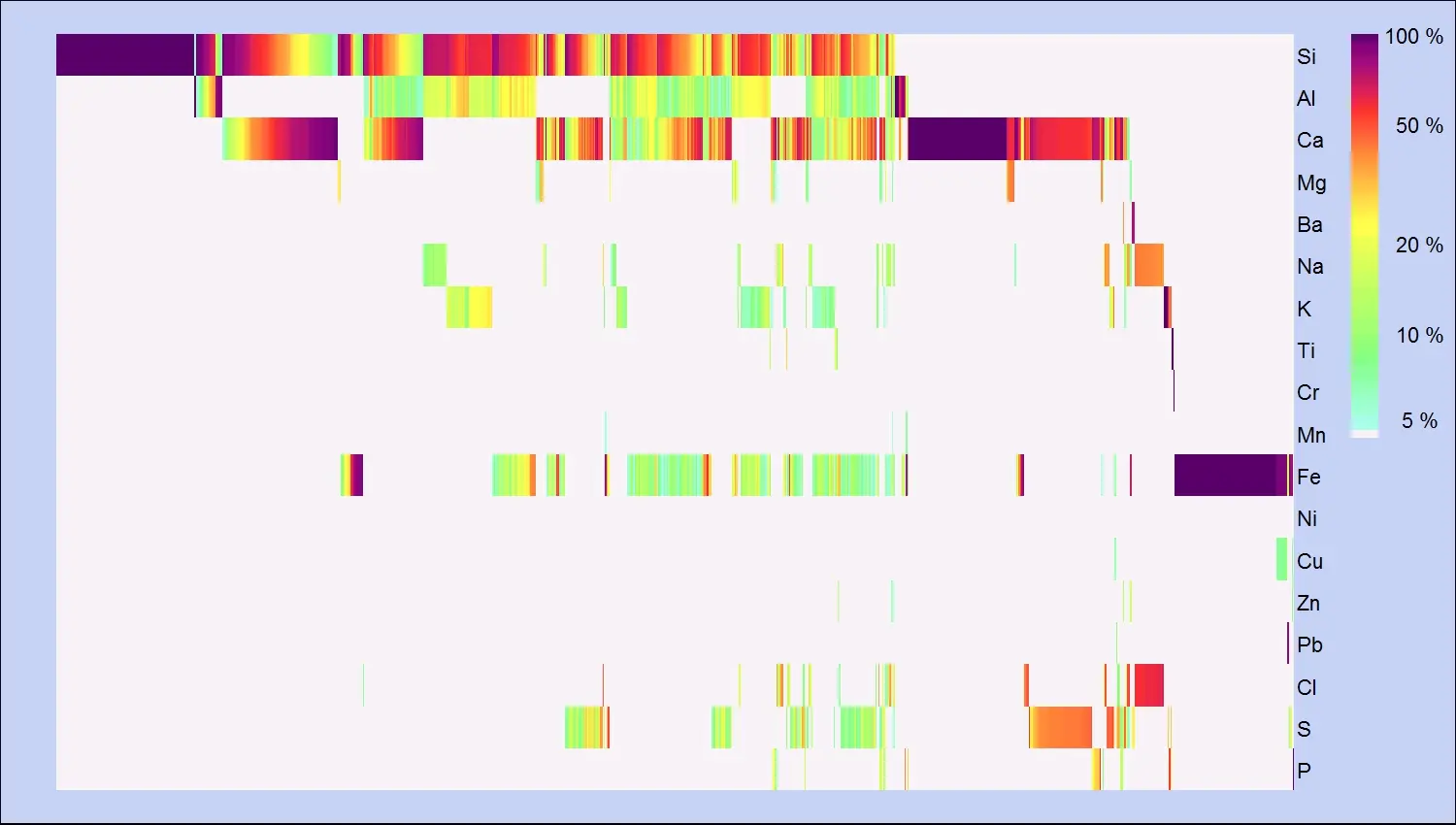
Entwicklung eines universell einsetzbaren dreistufigen Partikel-Klassifikator für Particle Vision GmbH, welcher die Partikel gemäss ihrer chemischen Zusammensetzung in mehrere tausend Klassen einteilt.
Details zum Projekt
Anonymisierung von Daten
Für die Weitergabe und interne Nutzung von Daten ist eine Anonymisierung erforderlich, um Rückschlüsse auf Einzelpersonen zu verhindern und gleichzeitig die Analysequalität möglichst zu erhalten. Diese Datenanonymisierung wird auf komplexe Daten der Helsana angewendet.
Details zum Projekt
Deep-Learning-basierte Klassifikation von histologischen Subtypen von Lungentumoren
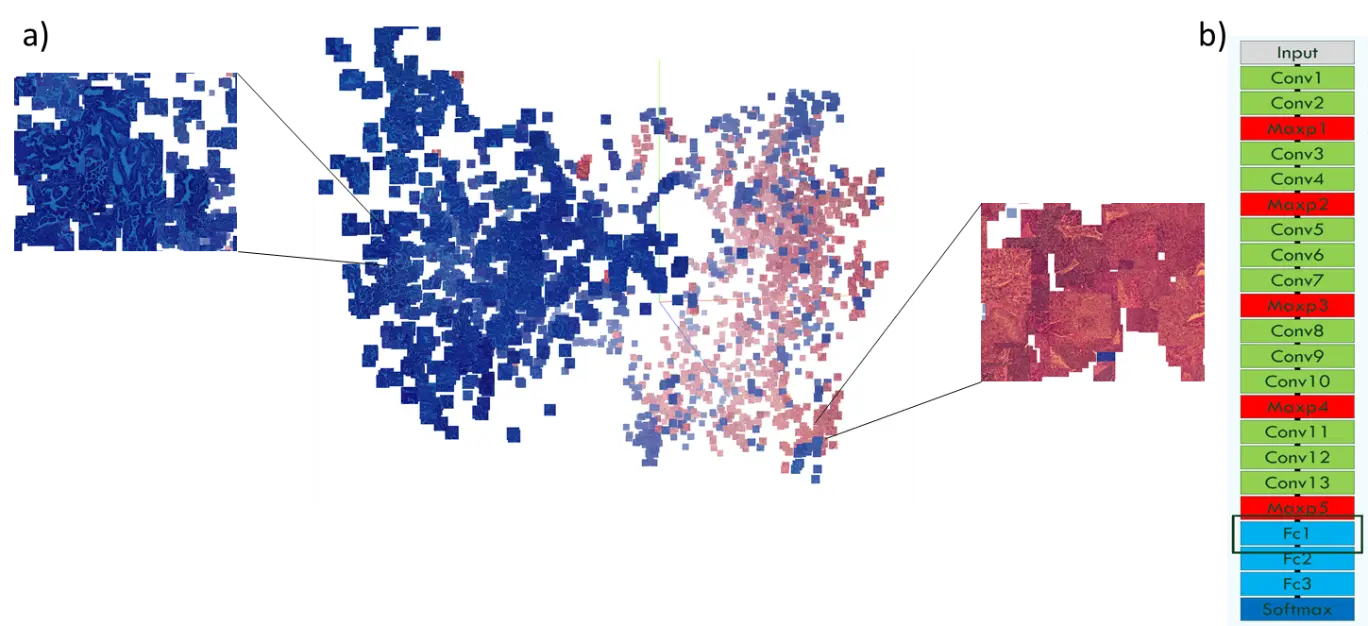
b) VGG‑CNN extrahiert 4.096 Bildmerkmale an der angegebenen Schicht.
Mehr Informationen unter Details zum Projekt.
Deep-Learning-Methoden (hier Convolutional Neural Networks) können anhand von Bildern histologischer Schnitte verschiedene Arten von Lungentumoren ähnlich gut wie Pathologen unterscheiden.
Details zum Projekt
Umsatzprognosen für die Gastronomie
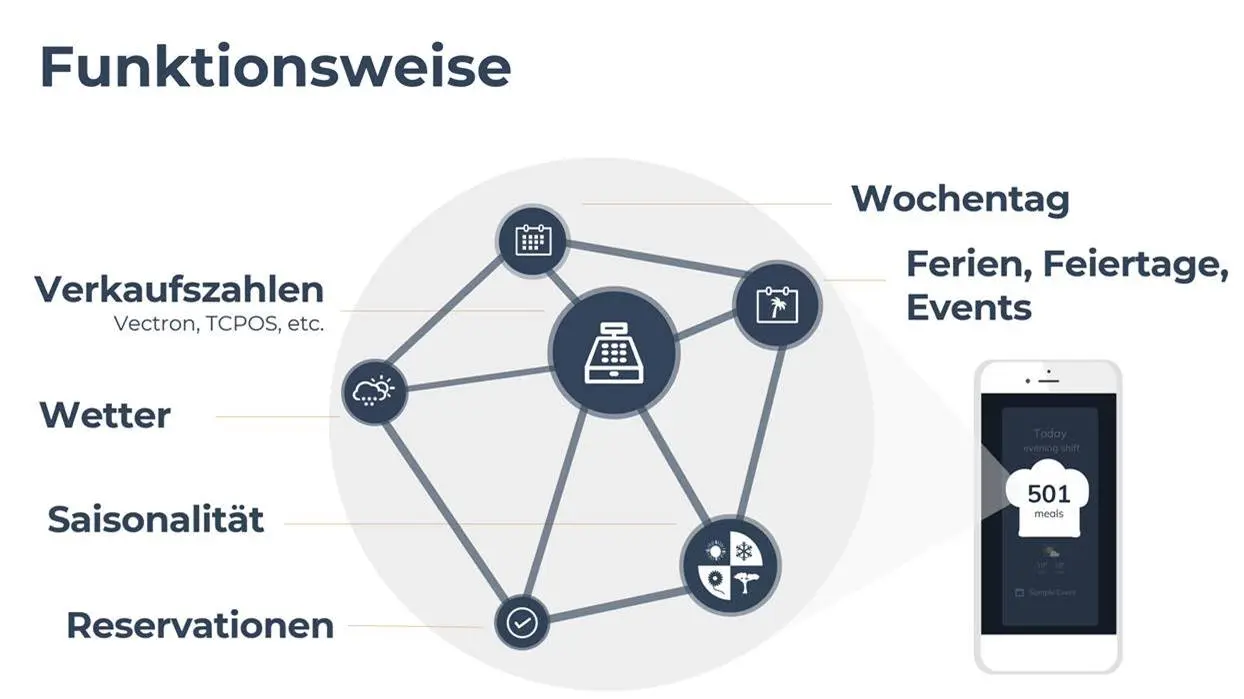
Entwicklung von Prognosealgorithmen, die Kalenderdaten, Wetter, Events und weitere Faktoren nutzen für Prognolite, Anbieter von Software zur Umsatz- und Frequenzprognose in der Gastronomie.
Details zum Projekt
Tarifsystem für die stationäre Rehabilitation
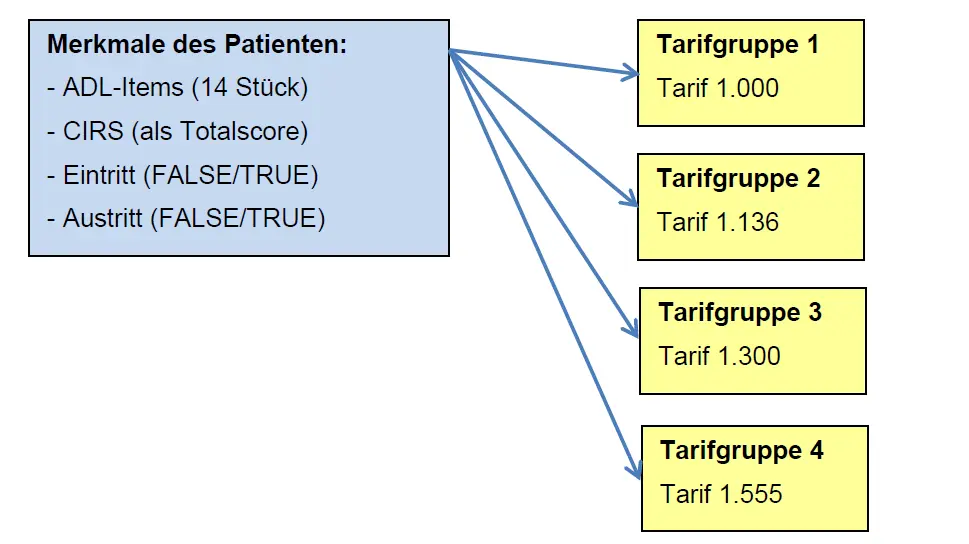
Im Rahmen der vom Krankenversicherungsgesetz vorgesehenen leistungsorientierten und pauschalisierten Vergütung von Spitälern und Kliniken hat die ZHAW ein Tarifsystem für leistungsabhängige Tagespauschalen in der Rehabilitation entwickelt.
Details zum Projekt
News
Keine Nachrichten verfügbar.
Publikationen
Ausgewählte aktuelle Artikel in wissenschaftlichen Fachzeitschriften (peer-reviewed)
Templ Matthias, Hofer Christoph, 2025. Compositional analysis of the relationships between the organic matter content and chemical and physical properties of soil. Applied Geochemistry. 193, S. 1-16. https://doi.org/10.1016/j.apgeochem.2025.106526
Spurk Christoph, Koch Carmen, Bürgin Reto, Chikopela Louis, Konaté Famagan, Nyabuga George, Sarpong Daniel Bruce, Sousa Fernando, Fliessbach Andreas, 2023. Farmers’ innovativeness and positive affirmation as main drivers of adoption of soil fertility management practices: evidence across sites in Africa. The Journal of Agricultural Education and Extension. https://doi.org/10.1080/1389224X.2023.2281909
Bürgin Reto, Muratori Corrado, Roca-Riu Mireia, Heitz Christoph, 2023. A space-time model for demand in free-floating carsharing systems. Journal of Advanced Transportation. 2023(6610624). https://doi.org/10.1155/2023/6610624
Arpogaus Marcel, Voss Marcus, Sick Beate, Nigge-Uricher Mark, Dürr Oliver, 2023. Short-term density forecasting of low-voltage load using bernstein-polynomial normalizing flows. IEEE Transactions on Smart Grid. 14(6), S. 4902-4911. https://doi.org/10.1109/TSG.2023.3254890
Mildenberger Thoralf, Braschler Martin, Ruckstuhl Andreas, Vorburger Robert, Stockinger Kurt, 2023. The role of data scientists in modern enterprises : experience from data science education. SIGMOD Record. 52(2), S. 48-52. https://doi.org/10.21256/zhaw-27357
Müller Werder Claude, Mildenberger Thoralf, Steingruber Daniel, 2023. Learning effectiveness of a flexible learning study programme in a blended learning design : why are some courses more effective than others? International Journal of Educational Technology in Higher Education. 20(10). https://doi.org/10.1186/s41239-022-00379-x
Ausgewählte aktuelle Artikel in wissenschaftlichen Fachzeitschriften (non-peer-reviewed)
Thalmann Basilius, Hofer Christoph, Wächter Daniel, Kulli Beatrice, 2022. Per- und polyfluorierte Alkylsubstanzen (PFAS) in Schweizer Böden. altlasten spektrum. 31(6), S. 176-179. https://doi.org/10.37307/j.1864-8371.2022.06.05
Ausgewählte aktuelle Projektberichte
Bürgin Reto, Stucki Michael, Vetsch-Tzogiou Christina, Kauer Lukas Kohler Andreas, Drewek Anna, Thommen Christoph, Dettling Marcel, Wieser Simon, 2024. Wirkungsanalyse zum Risikoausgleich mit pharmazeutischen Kostengruppen (PCG): Schlussbericht. https://doi.org/10.21256/zhaw-30489
Drewek Anna, Ordelt Christian, Riahi Nima, Sedding Helmut, 2024. 100 Jahre Sollzeiten - Ein Konzept für die Zukunft?. Logistics Innovation. 2024(1), S. 10-13.
Cieliebak Mark, Drewek, Anna, Jakob Grob Karin, Kruse Otto, Mlynchyk Katsiaryna, Rapp Christian, Waller Gregor, 2023. Generative KI beim Verfassen von Bachelorarbeiten: Ergebnisse einer Studierendenbefragung im Juli 2023. https://doi.org/10.21256/zhaw-2491
Ausgewählte aktuelle Vorträge (peer-reviewed)
Bürgin, Reto; Vetsch-Tzogiou, Christina; Stucki, Michael; Kauer, Lukas; Pirktl, Lennart; van Kleef, Richard C.; Kohler, Andreas; Drewek, Anna; Thommen, Christoph; Dettling, Marcel; Wieser, Simon, 2024. Improving risk adjustment in Switzerland with pharmaceutical cost groups [Paper]. In: 6th Swiss Health Economic Workshop, Lucerne, Switzerland, 7 June 2024.
Eine Übersicht aller Publikationen der Institutsmitglieder finden Sie in der Publikationsliste des Instituts.
Lehre
"Wir vermitteln Studierenden, wie sie mithilfe statistischer Methoden aus Daten lernen und dabei relevante Strukturen von zufälligem Rauschen unterscheiden können."
Lehrveranstaltungen
Wir vermitteln Bachelor-Studierenden umfassende Kenntnisse in statistischer Datenanalyse – von der explorativen Datenanalyse über statistische Inferenz, statistische Modellierung, fortgeschrittene Regressionsmodelle, Stichprobendesign und Analyse von Umfragedaten, Methoden des maschinellen Lernens für Klassifikation, prädiktive Modellierung, Data Analytics bis hin zur statistischen Qualitätskontrolle.
Unsere zentralen Lehrbeiträge liegen in den Bachelor-Studiengängen Wirtschaftsingenieurwesen, Mobility Science und Data Science. Ergänzend bieten wir zwei vertiefte Module im Master of Engineering an: Advanced Statistical Data Analysis und Business Analytics.
Darüber hinaus führen wir zwei CAS-Kurse durch: Data Analysis and Advanced Statistical Data Analysis, organisiert von der School of Engineering im Rahmen des MAS Data Science. Ergänzend dazu gibt es das R Boot Camp, einen kompakten Einführungskurs in R.
Betreuung von Studierendenprojekten
Wir freuen uns, mit Studierenden zusammenzuarbeiten und sie während ihrer Projektarbeiten engagiert zu begleiten – sowohl auf Bachelor- als auch auf Masterstufe (MSE).
Aktuelle Projekt- und Thesis-Möglichkeiten finden Sie auf Complesis.
Gerne entwickeln wir gemeinsam mit Ihnen Ihre Ideen weiter und setzen sie in spannenden Projekten um.
Team
-

ZHAW School of Engineering
IDS Institut für Data Science
Technikumstrasse 81
8400 Winterthur







