Eine einfache, preisgekrönte Idee, um datenhungrige Modelle zu zähmen
Forschende des ZHAW Centre for Artificial Intelligence (CAI) haben an der SDS 2025 den Preis für das beste «Full Paper» gewonnen – für eine einfache, aber wirkungsvolle Idee, die das Training von medizinischen Segmentierungsmodellen deutlich kostengünstiger macht.

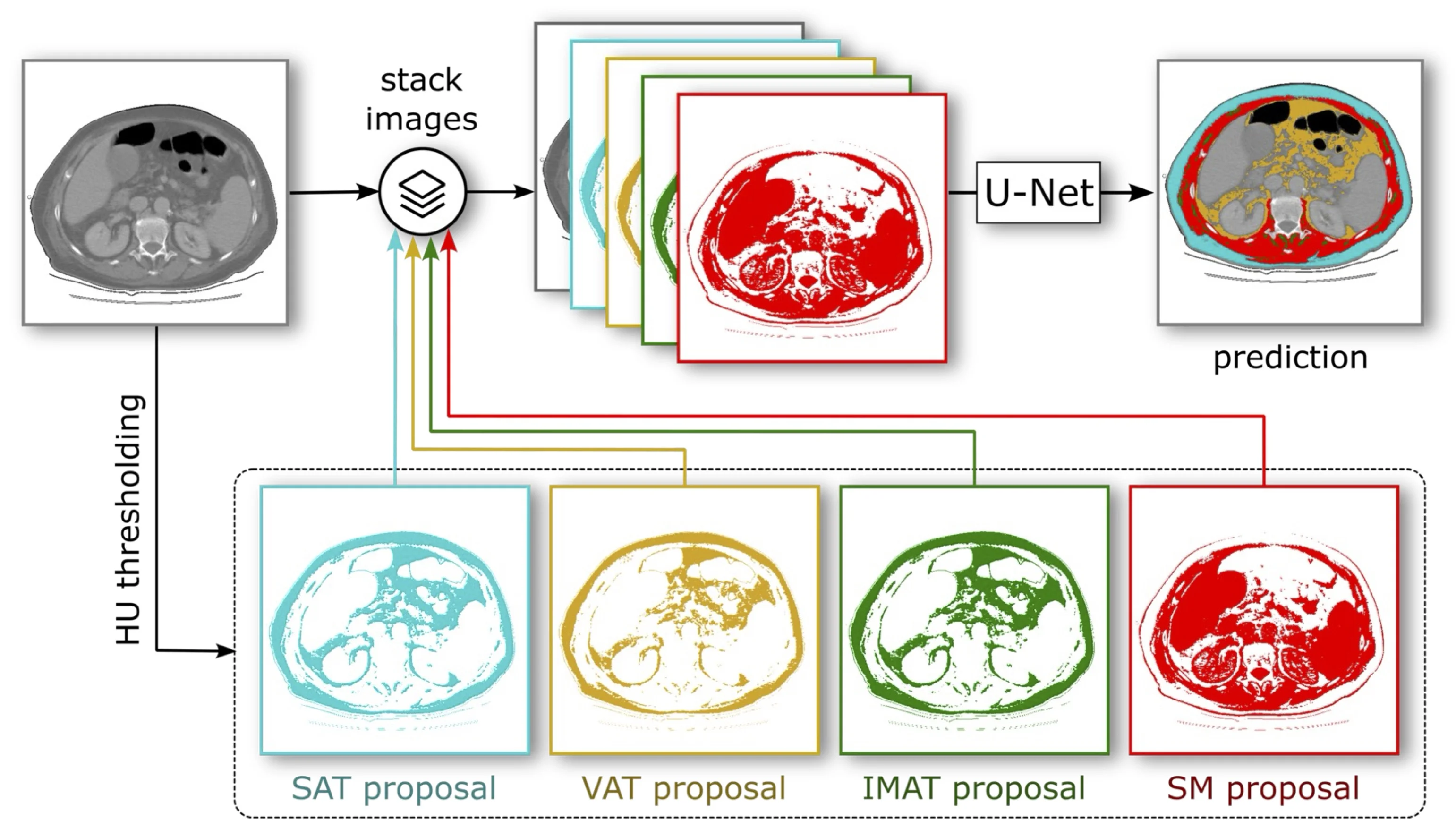
Im medizinischen Bereich werden Segmentierungsmodelle oft mit internen Daten von klinikspezifischen Geräten trainiert, um einen erfolgreichen Betrieb innerhalb der Klinik zu gewährleisten. Die Erstellung eines solchen internen Datensatzes ist jedoch teuer, da medizinische Experten die Daten zur Qualitätssicherung manuell «labeln» müssen. Wird der Trainingsprozess dateneffizienter gestaltet (d. h. die Anzahl der für ein erfolgreiches Training benötigten Datenpunkte wird reduziert), senkt dies direkt die Einstiegskosten für die Integration von KI-Modellen in die tägliche medizinische Praxis.
In Zusammenarbeit mit der Kantonsspital Aarau AG (KSA) wurde das CAI beauftragt, ein Segmentierungsmodell für medizinische CT-Bilder mit so wenig Daten wie möglich zu trainieren. Aus der Kombination der medizinischen Expertise des KSA und der Data-Science-Kompetenz des CAI entstand eine einfache, aber überraschend effektive Idee: Medizinisches Lehrbuchwissen wird dem Segmentierungsmodell als «inductive data bias» explizit zur Verfügung gestellt.
Konkret kodieren die Forschenden für jede Segmentierungsklasse (d. h. jeden Gewebetyp) den Bereich der Hounsfield-Skala aus der medizinischen Fachliteratur als binäre Maske. Diese Masken geben für jeden Pixel an, ob eine bestimmte Segmentierungsklasse medizinisch möglich oder unmöglich ist. Das Modell erhält diese Vorschlagsmasken als zusätzliche Eingangskanäle zum ursprünglichen CT-Bild und lernt während des Trainings, dieses zusätzliche Wissen erfolgreich zu integrieren.
Experimente mit diesem domänenwissensbasierten Feature-Engineering zeigen eine Verbesserung der Dateneffizienz von über 50 %. Das bedeutet, dass die vorgeschlagene Methode, trainiert auf nur der Hälfte der Daten, das Standardverfahren übertrifft. Diese Effizienzsteigerung halbiert die Kosten für die Datenkennzeichnung und senkt damit die Kostenschwelle für die Einführung dieser Methoden erheblich.
Diese einfache und zugleich wirkungsvolle Idee, etabliertes Fachwissen zur Steigerung der Dateneffizienz zu nutzen, lässt sich auch auf andere medizinische Bereiche (und sogar darüber hinaus) übertragen. Die Verallgemeinerung dieser Idee auf weitere medizinische Anwendungsfelder wird das Team in einem Folgeprojekt ab diesem Herbst untersuchen.