A simple, award-winning idea to tame data-hungry models
Researchers at ZHAW Centre for Artificial Intelligence (CAI) won the best full paper award at the SDS 2025 for a simple, yet powerful idea that makes training medical segmentation models significantly cheaper.

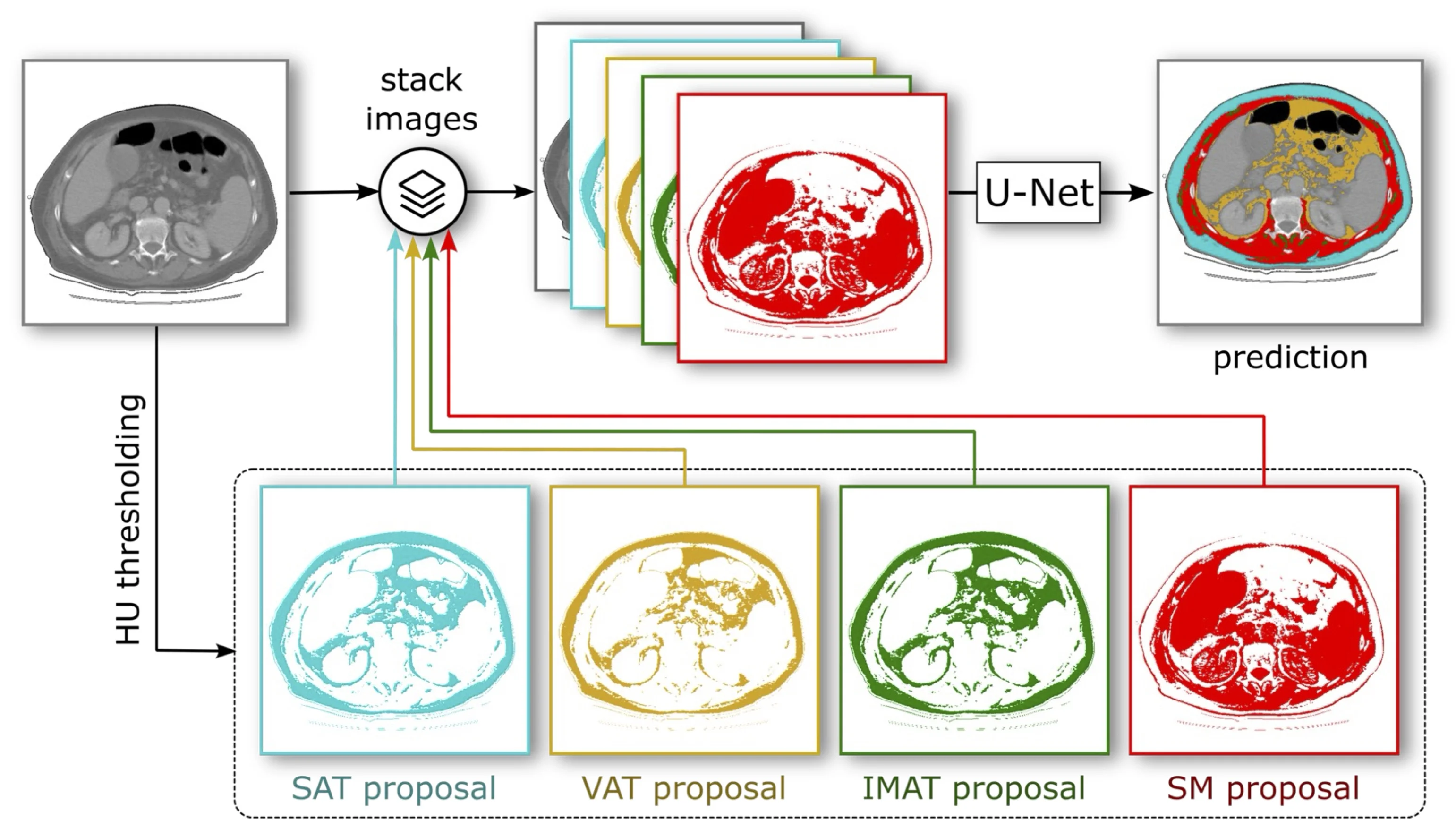
In the medical domain, one trains segmentation models on internal data from clinic-specific equipment to ensure successful operation in an intra-clinical setting.
However, collecting an internal dataset is expensive as medical experts must do labeling for quality control. Thus, making the training process more data-efficient (i.e., reducing the number of labeled samples required to train a model successfully) directly reduces the entry cost of integrating AI models into everyday medical practice.
In collaboration with Kantonsspital Aarau AG (KSA), the CAI was tasked with training a segmentation model for medical CT images with as little data as possible. A simple yet surprisingly effective idea emerged from combining medical expertise from KSA and data science expertise from CAI: making medical textbook knowledge explicitly available to the segmentation model as an inductive data bias.
Specifically, for each segmentation class (i.e., tissue type), the researchers encode the Hounsfield Unit range from the medical literature as a binary mask. These masks propose at each pixel location whether a specific segmentation class is medically possible or impossible. The model receives these proposal masks as additional input channels to the original CT image and, during training, learns to integrate this additional knowledge successfully.
Experiments with this domain-knowledge-based feature engineering demonstrate an improvement in data efficiency of over 50%, meaning that the proposed method, trained on only half the samples, outperforms the standard procedure. This improvement in data efficiency effectively cuts the labeling cost in half, significantly reducing the cost barrier for the adoption of these methods.
This simple yet powerful idea of integrating an inductive data bias for data efficiency can be generalized to other medical domains (and even outside the medical domain) by providing well-established domain knowledge in a non-restrictive form to the model. The generalization of this idea across other medical domains is something the team will investigate in a follow-up project starting this autumn.