Dokumentenerkennung als Transkription: Eine neue Perspektive
Eine Zusammenarbeit mit dem Schweizer Engineering-Spezialisten Bossard Group an einer digitalen Produktionsplattform für Bauteile offenbarte einen entscheidenden Engpass: die automatisierte Interpretation von technischen Zeichnungen. Diese industrielle Herausforderung initiierte eine Grundlagenforschung mit weitreichenden Auswirkungen auf die Bereiche der Dokumentenerkennung und die Entwicklung zukünftiger Foundation Models für Dokumente.
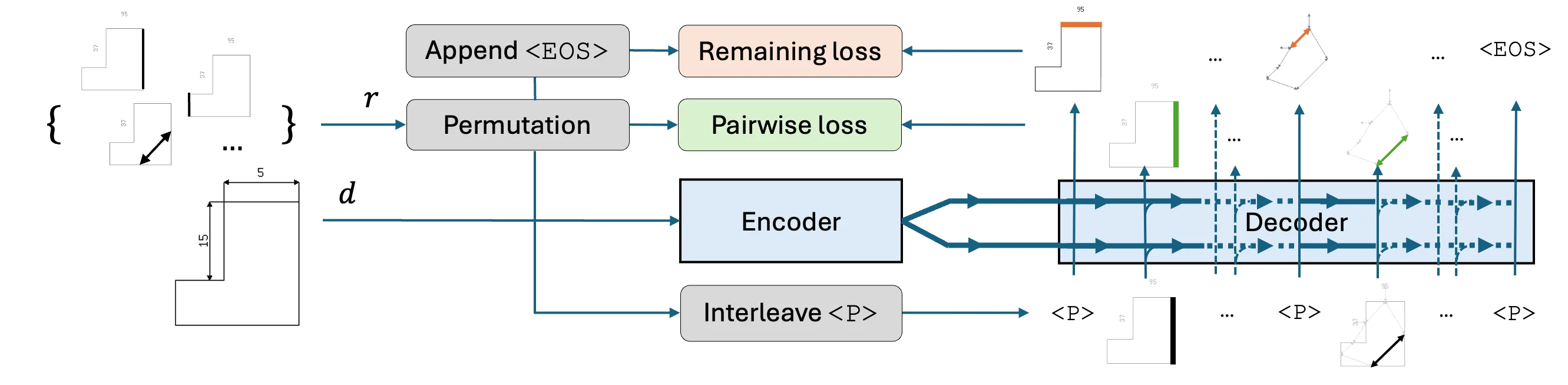
Viele spezialisierte Dokumente, wie technische Zeichnungen oder Notenblätter, folgen einem festen Regelwerk – einer Art "visueller Grammatik" –, um präzise Informationen zu vermitteln. Die meisten modernen KI-Systeme versuchen jedoch, sie durch die Behandlung als einfache Bilder zu verstehen, und fassen die Dokumentenanalyse als eine Computer Vision Aufgabe. Ein gängiger Ansatz verwendet beispielsweise die Objekterkennung, um einzelne Symbole zu finden, was jedoch inhärent unvollständig ist, da die wesentlichen Beziehungen zwischen Symbolen nicht erfasst wird. Infolgedessen sind diese Systeme auf eine suboptimale, heuristische Nachverarbeitung angewiesen, um die Bedeutung des Dokuments wieder zusammenzusetzen – ein Prozess, der bei vielen komplexen Dokumenttypen scheitert.
Unsere Forschung schlägt einen fundamentalen Perspektivwechsel vor, der die Dokumentenerkennung als eine Aufgabe der Transkription definiert. Dabei werden die visuellen Informationen eines Dokuments in seinen einzigen, zugrundeliegenden "Record" umgewandelt – die vollständigen, strukturierten Daten, die das Dokument vermitteln soll. Entscheidend ist, dass diese Transkription für standardisierte Dokumenttypen eindeutig ist. Während ein einzelner Record auf vielfältige Weise visuell dargestellt werden kann, lässt sich jedes gültige Dokument nur in den einzigen, korrekten Record zurückführen, was ein stabiles Lernziel für ein KI-Modell bietet.
Diese "Dokument-zu-Record"-Perspektive impliziert eine natürliche Gruppierung von Dokumenten basierend auf der intrinsischen Struktur ihrer Transkription. Um dies zu nutzen, haben wir eine Methode entwickelt, um diese Strukturen als induktiven Biases direkt in eine flexible Basis-Transformer-Architektur und den Trainingsprozess einzubetten. Wir demonstrieren die Wirksamkeit der so gefundenen induktiven Biases in umfangreichen Experimenten mit zunehmend komplexen Record-Strukturen von monophonen Notenblättern, Formzeichnungen und vereinfachten Technischen Zeichnungen. Durch die Integration eines induktiven Bias für die Struktur generellen Graphen trainieren wir das erste erfolgreiche End-to-End-Modell, das Technische Zeichnungen in ihre inhärent verknüpften Informationen transkribiert. Unser Ansatz ist relevant für die Gestaltung von Dokumentenerkennungssystemen für Dokumenttypen, die weniger gut verstanden werden als Standard-OCR, OMR usw., und dient als Leitfaden zur Vereinheitlichung des Designs zukünftiger Foundation Models für Dokumente.
Vollständiges Preprint: https://lnkd.in/ekPvsqE7
Für Infos zu unserem Partner: Bossard Group