Anonymisation of data sets from Helsana
Description
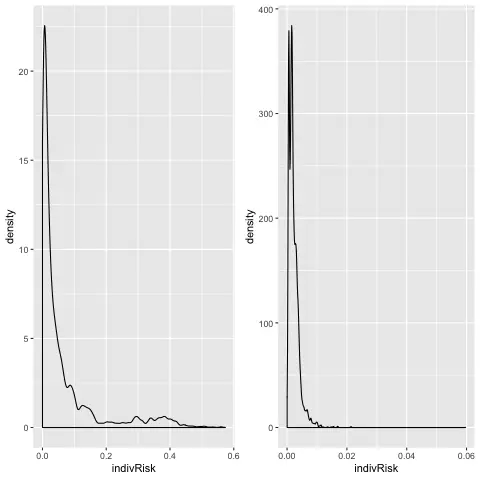
For sharing of confidential data as well as for the internal use of data anonymization is required, so that the conclusion on individuals is prevented and the analysis quality of the data is retained as far as possible. Data anonymization is applied to Helsana's complex data sets.Data in general but also data of Helsana Health Sciences used in analyzes internally and externally for far-reaching analyzes. Typically such kind of analyzes is often done for which the data were originally not intended at all or for which they were not collected.Quite centrally and in all respects the personal reference is the essential criterion when deciding on appropriate data transfer and data anonymization. Data without personal reference are excluded from the data protection laws and therefore one tries with anonymization to eliminate the personal reference.Such anonymization is by no means adequately fulfilled by perfect IT security and deletion or pseudo-anonymization of direct identification variables, such as name of the insured and AHV number, as soon as data is passed on internally or externally. Legislation has been explicitly stating for about two decades that the deletion of direct identification variables (or pseudo-anonymization of them) is by no means sufficient for person-specific data.First and foremost, the re-identification risk must be determined using probabilistic approaches. The decisive factor is the application of anonymization methods so that two goals are achieved at the same time: to decisively reduce the re-identification risk of persons and not to impair the data analysis quality of the data.The data contain billing information, information about the service deliveries and individual data insured as well as highly sensitive information.
Key data
Project partners
Helsana Versicherungen AG
Project status
completed, 08/2018 - 12/2018
Institute/Centre
Institute for Data Science (IDS)
Funding partner
Third party
Project budget
40'690 CHF