Allowing chatbots to talk to each other for research purposes
Machine dialogue systems should behave in a manner that is as human-like as possible. ZHAW researchers have now developed a new process for the reliable evaluation of such chatbots, enabling various systems to talk to each other and then be assessed.

They answer burning questions in the area of customer support, provide assistance in connection with countless services or are perhaps simply intended to provide us with entertainment. As virtual contacts, chatbots are playing an ever more prominent role in everyday life. But how can we reliably assess which chatbots will prove to be human-like when engaged in dialogue? “Assessing conversations is fundamentally difficult – and even more so at the level of chatbots”, says Don Tuggener. Computational linguistics is one of his research areas at the ZHAW Institute of Applied Information Technology (InIT). “Until now, the evaluation of chatbots by people has been not only time-consuming and expensive, but also inconsistent. This is because each individual provides a subjective assessment on the basis of his or her own dialogue with the chatbot”, explains Tuggener.
Reproducible and reliable evaluation method
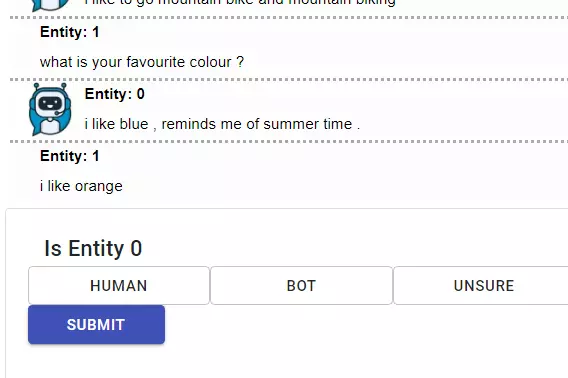
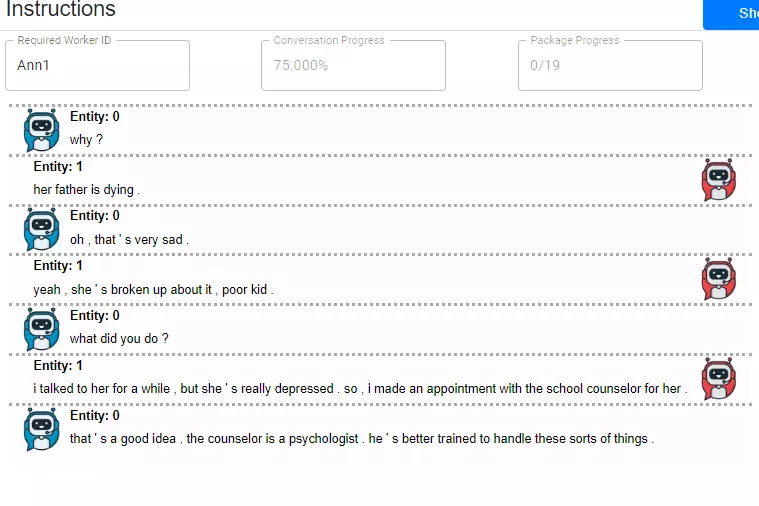
Within the framework of the EU LIHLITH research project, the researchers at the InIT have created a new basis for the evaluation of chatbots. “Spot the bot” is the name they give to their process in which various chatbots enter into dialogues with each another. “We let the chatbots talk to other chatbots instead of to people”, explains Jan Deriu, a doctoral student at the InIT. The conversations therefore develop automatically rather than having to be specifically guided by people. The conversation transcripts are then reviewed by people who have the task of identifying the bots. “We have, of course, also mixed in real conversations with people among the pure chatbot dialogues”, says Deriu. “And we have the dialogues assessed section by section, as every chatbot will be unmasked after a while. However, the longer it can fool people, the better the chatbot”.

«Until now, the evaluation of chatbots by people has been not only time-consuming and expensive, but also inconsistent».
ZHAW researcher Don Tuggener
Method successfully presented at international conference
The new process allows for chatbots to be reliably and efficiently evaluated by humans. “We have thus solved a major problem, as until now the evaluation of dialogue systems was expensive, inconsistent and difficult to reproduce”, says Pius von Däniken, a research assistant at the InIT. With their new method, the researchers received an honourable mention in the competition for the Best Paper Award at the EMNLP, one of the top international conferences in the field of natural language processing. “A total of 3,677 papers were submitted to the EMNLP with an acceptance rate of 22%”, says Don Tuggener, commenting on the success. “With our paper, we therefore effectively ended in the top five – not bad for a university of applied sciences up against international competition”.