Robust and efficient object detection method on video streams developed for critical care medicine
Research at CAI significantly improves video object detection efficiency and optimizes data quality for sensor-based patient monitoring at University Hospital Zurich
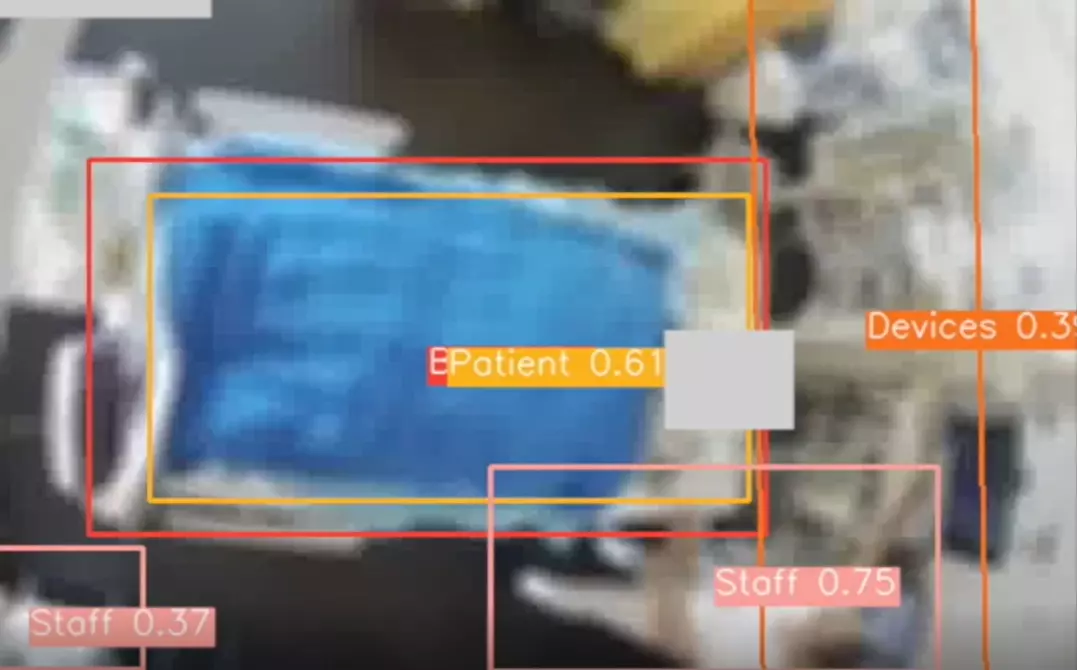
In the intensive care unit, patients are continuously monitored electronically so that an alarm can be raised immediately if, for example, a vital parameter leaves its target range. In the neurosurgical intensive care unit (NIPS) at the University Hospital Zurich (USZ), an average of 700 alarms sound per day and patient. The high number of alarms often places unnecessary strain on medical staff and ties up valuable time. In order to reduce the burden on staff in the future, an IT infrastructure has been set up at the USZ to record monitoring data and develop digital systems for clinical support. However, it is becoming apparent that these systems are susceptible to artifacts in the measured signals, which can be caused by patient movement or medical interventions. Moreover, such artifacts in themselves are difficult to distinguish from physiological patterns, even for humans. In contrast, it is much easier to be right at the bedside and see the context in which a particular signal is measured.
In order to make exactly this context available for the research and development of future support systems and thus make them more resilient, an object recognition system that can extract contextual information from video data was developed in the recently successfully completed DIZH-funded project AUTODIDACT. Video data that is already available at NIPS, as at many modern intensive care units, since patients are monitored with cameras as standard at these units.
Contextual information was defined at the beginning of the project as the recognition of the bed, the patient, and the nursing staff and medical equipment. To protect the privacy of patients and medical staff, object recognition had to be based on blurred video. As a result, a completely new object recognition model had to be developed, since already trained artificial intelligence (AI) systems for object recognition were only available for high-resolution images.
For this purpose, blurred video data was first recorded as training data with the consent of patients and annotated in these by humans. Based on these videos, a YOLOv5 model (an AI system for object recognition that is considered a quasi-industry standard) was then trained in a first approach to establish a baseline. In this approach, object recognition is done on the basis of individual images. Although the recognition for blurred images was relatively good, it could be further improved in a second approach: The improvement was achieved by taking into account the temporal progression over several images. For this purpose, the three input channels blue, red, green of the YOLOv5 model were replaced by other image information. The red channel was replaced with the black and white image, the green with the pixel changes between the previous image and the blue with the positions of the previously detected objects. This "trick" then resulted in a model that was much faster to train and provided more stable and accurate results overall, which also benefited the limited hardware resources.