Bachelorarbeit Informatik: Erstellung von Dialog-Systemen mittels Sequence-To-Sequence Learning
«What are you?» – «I‘m a bot.»
In ihrer Bachelorarbeit in Informatik haben sich Dirk von Grünigen und Martin Weilenmann mit künstlicher Intelligenz und Deep Learning auseinandergesetzt. Sie haben ein Dialogsystem – einen sogenannten Chatbot – aufgebaut. Über grosse philosophische Fragen diskutieren kann man mit ihm nicht, ein bisschen plaudern aber schon.
Mit einem Computer gemütlich über Filme fachsimpeln: Was vor ein paar Jahren noch als ferne Zukunftsmusik galt, liegt heute im Bereich des Möglichen. Die beiden Informatik-Absolventen Dirk von Grünigen und Martin Weilenmann haben sich genau mit dieser Thematik auseinandergesetzt. Die beiden haben es sich in ihrer Bachelorarbeit zum Ziel gesetzt, ein Dialogsystem – einen sogenannten Chatbot – aufzubauen. Dabei haben sie Methoden des maschinellen Lernens eingesetzt, sogenannte Recurrent Neural Networks. Dabei legt sich der Computer anhand von Trainingsdaten quasi selbstständig Strategien zur Lösung von Aufgaben zurecht und kann diese später auf neue Daten anwenden. Dirk von Grünigen erklärt: «Neuronale Netze werden bereits bei verschiedensten Aufgaben im Alltag eingesetzt, etwa wenn ein Computer ein Gesicht auf einem Foto automatisch erkennen soll. Recurrent Neural Networks eignen sich speziell zur Verarbeitung und Generierung von Text, da diese aufgrund ihrer Architektur die Möglichkeit besitzen mit der unterschiedlichen Länge und Form von Sprache klar zu kommen.»

Reddit-Kommentare und Untertitel
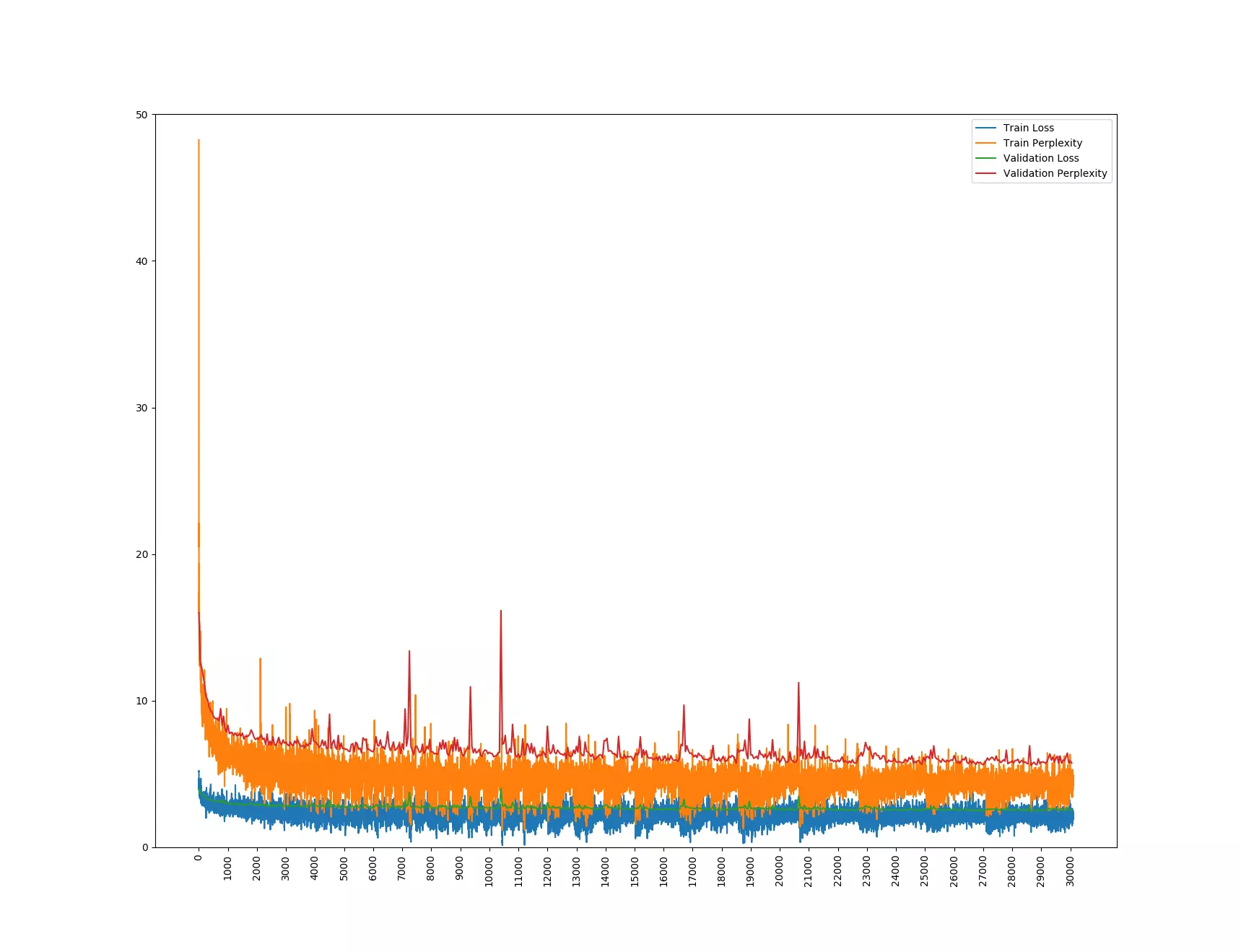
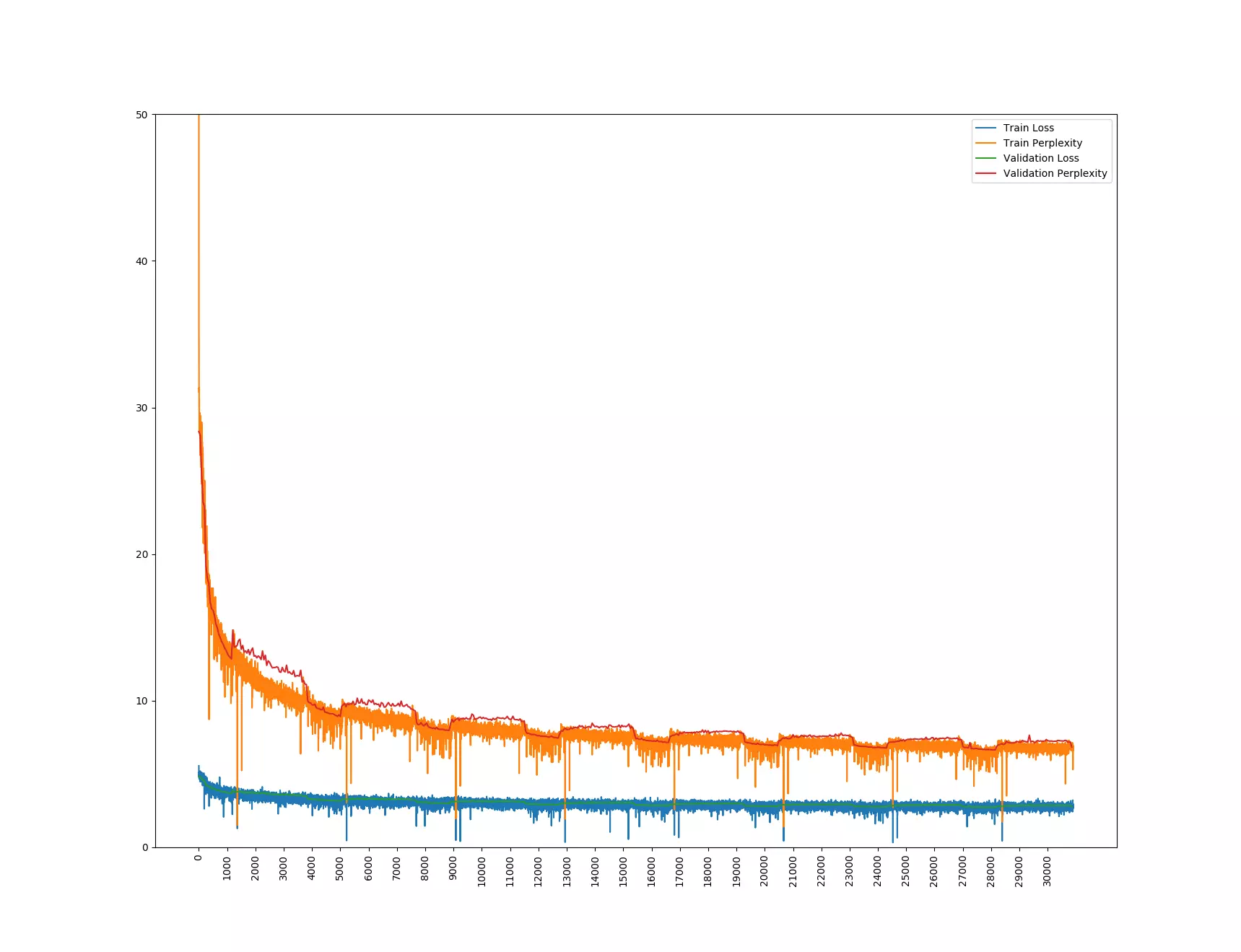
Den Chatbot fütterten die beiden Absolventen mit Daten aus zwei verschiedenen Quellen: zum einen Kommentare der Internetplattform Reddit mit Bezug zu den Themen Film und Fernsehen, zum anderen Untertitel von Filmen. Allein aus letzterer kamen insgesamt 350 Millionen Sätze zusammen. Dabei hat sich gezeigt, dass der Bot nicht mit beiden Quellen gleich gut umgehen konnte. Martin Weilenmann erklärt: «Der Chatbot lernte mit den Reddit-Daten besser als mit den Untertiteln und lieferte schneller sinnvolle Resultate. Die Ursachen dafür müssen in den Unterschieden der Trainingsdaten zu finden sein. Einerseits handelt es sich bei den Reddit-Daten um geschriebene, bei den Untertiteln um gesprochene Sprache. Andererseits sind die Reddit-Daten wesentlich besser strukturiert und es ist ersichtlich, dass es sich beispielsweise bei einem Kommentar um eine Replik auf einen anderen Kommentar handelt.»
«Je länger wir den Bot trainierten, desto besser und vielfältiger wurden auch die Antworten.»
Dirk von Grünigen
Drei Wochen Training
Drei Wochen dauerte das Training, dabei wurde der Lernfortschritt laufend überprüft. In regelmässigen Abständen stellten die beiden Absolventen dem Chatbot die gleichen Fragen: «What are you?» «Is 5 greater than 3?» «What color is the sky?» Die Antworten auf diese und viele weitere Fragen analysierten Dirk von Grünigen und Martin Weilenmann anschliessend mit einem mathematischen Modell, das die Ähnlichkeit der Chatbot-Antwort mit einer erwarteten Musterantwort vergleicht und entsprechend bewertet. Dirk von Grünigen berichtet: «Zu Beginn des Trainingsprozesses gab uns der Chatbot noch viele generische Antworten wie ʹI don’t knowʹ. Das führte zu eher schlechten Messwerten. Je länger wir den Bot trainierten, desto besser und vielfältiger wurden auch die Antworten, so dass er zum Schluss etwa auch die Frage ʹWhat are you?ʹ korrekt mit ʹI‘m a botʹ beantwortete.»
Resultate mit anderen Chatbots vergleichbar
Ihre Ergebnisse verglichen die Absolventen dann mit denjenigen des Online-Chatbots Cleverbot und den Resultaten einer Studie zum Thema Chatbots. «Dabei zeigte sich, dass unsere Modelle vergleichbar gute Ergebnisse wie die anderen Systeme liefern – vorausgesetzt, die Dialoge sind nicht zu komplex», sagt Martin Weilenmann. «Das liegt vor allem daran, dass unser System deutlich kleiner konzipiert wurde als andere», ergänzt Dirk von Grünigen. Schliesslich hätten die Chatbots in der erwähnten Studie zum Beispiel sogar brauchbare Antworten auf so komplexe und abstrakte Fragen wie derjenigen nach dem Sinn des Lebens gefunden. «Die anderen Systeme konnten mit grösseren Datenmengen arbeiten und hatten viel mehr Zeit für das Training ihrer Chatbots. Unser System ist dafür ressourcensparender. Darum können wir mit unseren Ergebnissen dennoch sehr zufrieden sein.»
Weitere Informationen
Infotage und Anmeldeschluss Bachelorstudiengänge
Infoveranstaltungen
- Samstag, 09.11.2024 (Infotag Bachelorstudium)
- Dienstag, 26.11.2024 (Online-Infoabend Bachelorstudium)
Anmeldung zum Bachelorstudium
Das könnte Sie auch interessieren
Aufnahmebedingungen
Die Aufnahmebedingungen für das Bachelorstudium an der ZHAW School of Engineering.
Studiumsvorbereitung
Erfahren Sie, wie Sie sich optimal auf das Bachelorstudium vorbereiten können.
Anmeldung zum Bachelorstudium
Aufnahmebedingungen
Studiumsvorbereitung
Melden Sie sich jetzt zum Bachelorstudium an.
Die Aufnahmebedingungen für das Bachelorstudium an der ZHAW School of Engineering.
Erfahren Sie, wie Sie sich optimal auf das Bachelorstudium vorbereiten können.